The Run(chart)ing Man (Last updated: 2025-04-24)
Measurement for improvement in healthcare with R and Qlik
My not so secret obsession
Anyone in the small subset of the Earth’s population who both read this blog AND follow me on Twitter will know that I spend a lot of time at work either producing or analysing run charts, which we use to determine if our quality improvement work is genuinely assisting us achieve our target outcomes.
A run chart is essentially a line chart, with an initial baseline median plotted and extended into the future. Then, as the improvement work continues, you continue to plot the data and look for certain patterns within the data which are statistically unlikely to occur by chance.
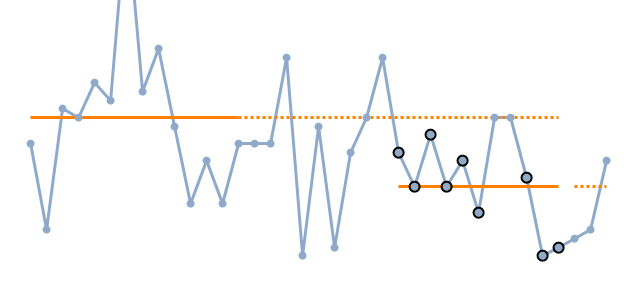
Here’s an example (minus the date axis and the y-scale):
Take a look at the link above and you will see graphics demonstrating the 4 rules (shift,trend, too few runs, extreme data point).
For a long time I’d been thinking about how to automate the process of identifying sustained runs of improvement (signified in this case using the IHI run chart rules of 9 consecutive points on the appropriate side of the median), and then calculating a new improvement median from these points.
I’ve actually written SQL queries to automate most of this - including finding the first improvement median but not automatically finding every re-phased run beyond that (e.g. phase 2, then phase 3 etc) without resorting to recursion or looping. Which, as in R, is frowned upon. However, unlike R, calculating medians when there is no native median function (SQL Server 2008 R2) is a bit of a challenge, along with finding trends and every run for comparison with the “too few runs” rule. Got there in the end, and it improved my SQL skills no end, but SQL is not the right tool for the job.
I should mention the fantastic qicharts package, which allows you to create virtually every chart you would require, with a host of options. I’ve used this lot, and recommend it. It has some very robust rules built in to identify improvements. It will produce faceted plots, and allows you to specify different periods over which to calculate medians - so, if a an improvement is noted, you can calculate a new median from that point onwards.
Because of the volume of metrics I have to track, it’s not possible (or at least, not desireable) for me to manually specify different improvement ranges for each set of metrics.
So, for the last wee while, I’ve been working away at automating all this using dplyr and ggplot2.
I wondered if this could be done in a one-shot, vectorised approach.
I googled.
I considered data.table, which may very well be the ideal package to do the work.
I saw various other possible approaches and solutions.
I obsessed over whether I could vectorise it, and if not, would it make me a Bad Person.
And then I stopped worrying about it and just cracked on with dplyr.
I wrote many functions.
I learned some basic R functions that I didn’t know existed (need to RTFM at some point).
I wrote complex base R that future me is going to hate me for, even with the comments.
I grappled with Non Standard Evaluation and Lazy evaluation.
I laughed.
I cried.
I nearly hurled (see Non Standard / Lazy Evaluation).
And finally, I came up with not one but 2 different R based approaches.
The first one is less dplyr intense and works for just one plot at a time - ideal for ad-hoc analysis and plotting of a simple vector. And it’s quick too:
I also produced a slightly more heavy duty approach for faceted plots within ggplot2 using dataframes. For one of my metrics I now have run-charts across 99 seperate locations, all plotted nicely in A3 with re-phased medians. I was literally punching the air the first time I saw this magic plot appear on my monitor. From start to finish - the analysis and plotting/saving to pdf took around 20 secs. Not too shabby.
I’ve also been digging in to QlikView a bit more recently. Just over a week ago I sat down to see if I could crack this in QlikView. Here is my progress so far:
A simple run of 9 in a row identified and higlighted:
These pesky points on the median gave me some grief. Ignoring these, in various combinations,was by far the hardest part to implement:
From my work with QlikView, I’m going to go back to my R code and see if I can make any more improvements. It’s great how different tools can inspire you to new ideas and looking at things a different way.
I’m not going to stick any code up just yet - but maybe might have a package in the works. I understand that NSE in dplyr is getting revised so I’m going to wait to see what transpires.
In the meantime though - for blazing fast interactive analysis on the fly for any combination within my data set - I can use QlikView.
And for static reports at scale, or simple ad-hoc analysis, yet again, its R, and the ggplot2 / dplyr super-combo that gets the job done.
NB - for those who have arrived here through google, there is a now a runcharter package, designed to create many run charts at once, and perform the shift analysis. You can find out more about it here: johnmackintosh.github.io/runcharter