PreppinData - accepting the challenge with R and PowerBI (Last updated: 2025-06-25)
I’ve completed a month of ‘PreppinData’ challenges, using both R and PowerBI. Some things have been easy, some have not - here’s what I’ve learned in Week 1
I had the good fortune of stumbling across a tweet by the organisers of PreppinData This is a bit like Tidy Tuesday, except it’s focussed more on data preparation than data visualisation. Ostensibly, it’s for people to get to grips with Tableau’s data preparation tool, but the organisers are open to other solutions using other tools.
PreppinData struck me as a useful exercise:
- 80% of data work is data prep/ munging/ manipulation
- I’m mainly working with SQL at work at the moment, so I need a way to keep my R chops in some kind of shape
- I’m getting my feet wet with PowerBI, so I figured I could try the challenges in R first, and then see how far I could get in PowerBI.
I am pretty much starting from scratch with PowerBI. I spent my Christmas holiday period working through a course I’d purchased on Udemy (I’m quite big on self directed training - though usually it’s R related).
This course was significant as
- it’s the first time I’ve ever completed a Udemy course
- it’s the first time I’ve kept PowerBI open longer than 10 minutes.
Self directed training is fine, but we all know you don’t LEARN until you have to deal with someone else’s messy data and their associated problems.
Week 1
The first week challenge involved importing data from a google sheet, splitting a column into two, recoding existing variables, creating some date fields, and a summary.
It was all pretty easy with R.
In fact, it was so straightforward, I decided to be as minimal as possible - so rather than use tidyverse, I tried to do it all with data.table and base R functions.
There’s no reason for this of course, other than me imagining how I would fare if I was in the unlikely scenario that I had to write R code IN ORDER TO SAVE THE WORLD, but wasn’t allowed to use {tidyverse}.
I mean, how would YOU cope?
Leaving aside this hypothetical nonsense, the main things to note from week 1 were
- I used the {gsheet} package for simple downloading of data without having to log in to Google Drive. It can be read in as a text file or a dataframe. This downloads the data from a specified link as a tsv file:
import <- gsheet2text(link, format = 'tsv') I used ‘tstrsplit’ to split the column into 2 based on a hyphen delimiter - as an alternative to {tidyr}'s separate function. It’s a lit bit more invoved than separate.
Here I’m splitting a column named Store - Bike into two columns
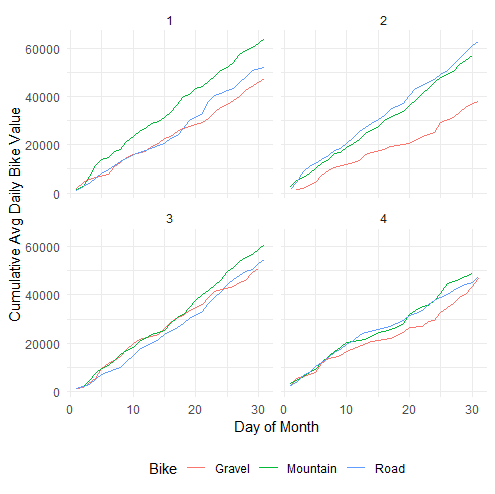
DT[, c("Store", "Bike") := tstrsplit(`Store - Bike`, " - ", fixed = TRUE)][,`Store - Bike` := NULL] There was a bonus exercise, to work out a cumulative value, and plot it.
DT2[, cumulative := cumsum(daily_average), by = .(Quarter,Bike)][] ggplot(DT2,aes(Day_of_Month,cumulative, colour = Bike)) + geom_line() + facet_wrap(~ Quarter, ncol = 2) + labs(x = 'Day of Month', y = 'Cumulative Avg Daily Bike Value') + theme_minimal() + theme(legend.position = 'bottom')
PowerBI
Importing the data was straightforward, as was most of the manipulation, once I’d oriented myself.
I think the hackiest part was the tidying up of the bike type column - there were various mis-spellings of the 3 main categories. Rather than a complex regex, I went with simply using the first letter and recoding based on that:
Table.AddColumn(#"Renamed Columns", "Bike2", each if Text.StartsWith([Bike], "R") then "Road" else if Text.StartsWith([Bike], "M") then "Mountain" else "Gravel") I had a heck of a job trying to group and sort the values by Quarter and Day.
I even tried hacking together an index column, which helped me get a cumulative plot originally, but it looked awful.
Unless I missed it, I could only see a way to sort by one column using the toolbar, and not an Excel style way to specify multiple ones..
In terms of the table visual, I learned you could sort by left clicking SHIFT plus the column header, and then repeating that for any others.
I’m sure there is a way of doing it in the ‘M’ / PowerQuery language being used to do the data transform, but I haven’t chanced across that yet.
The other bit that stumped me was creating a cumulative column.
During the course, I’d been introduced the ‘iterator’ functions.
I was hoping not to have to use those, as they were at the tail end / advanced bit of the course.
Fortunately, I follow Will Thompson (Microsoft Program Manager for PowerBI) and he is also sharing his solutions for these challenges.
Someone replied to him that a quick measure could be used, so I went with that, but it looked like you could only use one grouping column.
I need to get values by Quarter and Bike.
In the end, with some more research, I got this measure together, which avoided an iterator function (although not for long) :
Running Total = CALCULATE( SUM(Summary[Daily Average]), FILTER( ALL ('Summary'), 'Summary'[Bike]= max('Summary'[Bike]) && 'Summary'[Day] <= Max('Summary'[Day]) && 'Summary'[Quarter] = MAX(Summary[Quarter] ) )) I’ve no idea if this good / bad/ downright awful, but it worked.
This measure was part of a summary table for the final plot, created using DAX:
Summary = SUMMARIZECOLUMNS( input[Bike], input[Quarter], input[Day], "Daily Average", AVERAGEX(Input,input[Bike Value]) ) The really cool part was I could then use a small multiple to plot these.
Small multiples are a new feature in PowerBI (as of the Dec 2020 release) and they are really well done.
They look good, and I managed to get it to work with minimal effort:
Admittedly, the title of the plot is not great, far from it, but in this instance, I was happy to get to this point.
That’s enough for this post.
In my next post, I’ll cover my learning in both R and PowerBI for weeks 2-4.
Let me know if you enjoyed this by following on Twitter or connecting on LinkedIn