Even Simpler SQL (Last updated: 2025-05-03)
A follow up post, with improved SQL and dplyr code
I’ve had some feedback on the last post, and rather than repeat the same thing multiple times, I’m going all @drob, and writing this instead..
When I tweeted out the link to my post I gave it the tag line “why I’d rather write dplyr than SQL”.
What I couldn’t fit in to the tweet was that this was based on the caveat that some of the SQL I have had to write has been incredibly complicated by the age / version / lack of functionality of the SQL database I was using, and the nature of the task at hand.
In those situations, being able to write dplyr to manipulate my data would have made my life a lot easier.
However, I am not against SQL.
Far from it, I love working with SQL and writing complex queries.
The more you learn, the more you understand what can be done with SQL, and it’s incredibly powerful.
But - there are definitely times when you think, “this would be a lot easier in R”.
TL / DR :
SQL is great, and you should definitely learn it
AND
Dplyr is great, and you should definitely learn it.
Then you can decide which is best for the situation you are currently facing. In real life you wouldn’t need a hugely powerful database to wrangle 684 rows, and my main reason for using dplyr was that it was a small dataset and the resultant table was going to be assigned to ggplot2 for plotting purposes.
Less code, same results
I realised the SQL code I demonstrated for the final query was a bit convoluted, mainly because I wanted people who are new to it to be able to follow the code ( which hopefully they did).
However that final query could have been a lot more succinct. Here was the first part:
SELECT * , ROW_NUMBER() OVER (PARTITION BY IN_OUT, Movement_Type,Staging_Post,Movement15 ORDER BY (MovementDateTime)) * [counter] AS Movement_15_SEQNO FROM ( SELECT [MovementDateTime], [FirstName], [LastName], [Ward_Dept], [Staging_Post], [Movement_Type], [IN_OUT], CAST(round(floor(CAST([MovementDateTime] AS float(53))*24*4)/(24*4),5) AS smalldatetime) AS Movement15, (CASE WHEN IN_OUT = 'IN' THEN 1 ELSE -1 END) AS [counter] FROM [SERVER].[dbo].[TABLENAME])x ORDER BY MovementDateTime Having specified the necessary columns within that first query, we can simply do a
SELECT *, ROW_NUMBER() OVER (PARTITION BY IN_OUT, Movement_Type,Staging_Post,Movement15 ORDER BY (MovementDateTime)) * [counter] AS Movement_15_SEQNO to add in the new column.
This time round, we are creating the row number column and multiplying it by the counter field in 1 step.
So this gives us a much shorter query, (as we are removing 1 level of nesting, and not specifying each column in the subsequent levels). It runs to only 14 lines, compared to the 37 in the final query last time round. Here’s the new , final version:
SELECT * , ROW_NUMBER() OVER (PARTITION BY IN_OUT, Movement_Type,Staging_Post,Movement15 ORDER BY (MovementDateTime)) * [counter] AS Movement_15_SEQNO FROM ( SELECT [MovementDateTime], [FirstName], [LastName], [Ward_Dept], [Staging_Post], [Movement_Type], [IN_OUT], CAST(ROUND(FLOOR(CAST([MovementDateTime] AS FLOAT(53))*24*4)/(24*4),5) AS SMALLDATETIME) AS Movement15, (CASE WHEN IN_OUT = 'IN' THEN 1 ELSE -1 END) AS [counter] FROM [SERVER].[dbo].[TABLENAME])x ORDER BY MovementDateTime But wait.
We can also make our dplyr code even simpler.
One of the comments on my last post suggested that we should use if_else(), instead of case_when() for creating the counter field. And that is a great suggestion, because there are only 2 possible values that the IN_OUT column can have.
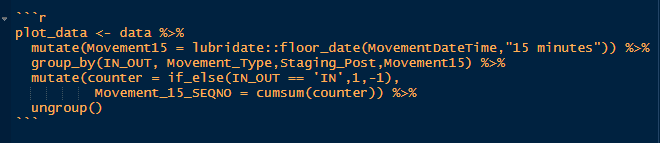
In addition, having created the counter field, we can make use of it straight away to create the sequence number within the same pipe. So our final dplyr code, (which works), looks like this:
plot_data <- data %>% mutate(Movement15 = lubridate::floor_date(MovementDateTime, "15 minutes")) %>% group_by(IN_OUT, Movement_Type, Staging_Post,Movement15) %>% mutate(counter = if_else(IN_OUT == 'IN', 1, -1), Movement_15_SEQNO = cumsum(counter)) %>% ungroup() 6 lines, compared to 8 in the previous example.
Its not really THAT big a deal for this example, but its as well to be aware that you could simplify further if you wanted to. As always, get stuff working first, then optimise it as needs be.
If you want really concise and powerful R code, which is even more ‘SQL like’, then you should look at data.table.
I haven’t used it a lot, but even with the short amount of time I devoted to it, I found I could write less code and see hugely impressive speed of execution , so if you get to the point where you really want to strip everything down then you will probably end up getting familiar with DT and its syntax.