Enter Sa(n)dMan (Last updated: 2025-05-17)
Yet more Metallica sentiment analysis - wrapping up the last post with additional plots.
I’m just going to tidy up some issues from my last post where I did some tidytext analysis on the legendary rockers - Metallica.
It was a fun way to pass some time and keep my hand in with text mining, something I still don’t seem to get around to doing in the day job.
I was pretty annoyed at not getting my faceted split of top terms by descending order to plot by actual descending order.
Attempt 1:
Many failed efforts later, I arrive at this:
Attempt 2 -getting better, but still not right. Julia, in the unlikely event you read this, WHAT am I doing wrong?
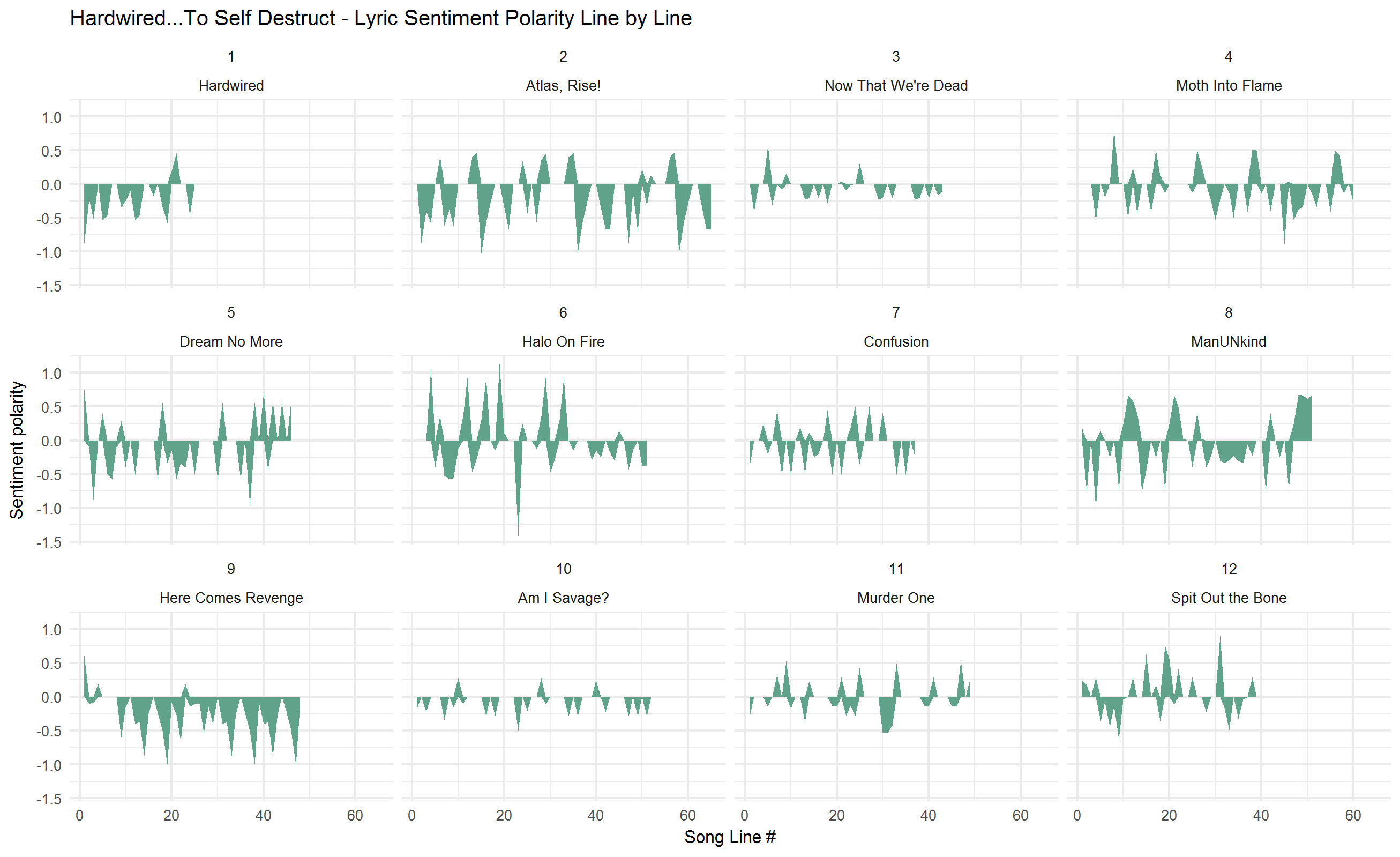
Enough of my failures (not enough time, folks) lets look at sentiment on a line by line basis, instead of just a net score by track. To do this, I used the sentimentr package, by Tyler Rinker.
Stolen from the the package homepage on GitHub: “sentimentr is designed to quickly calculate text polarity sentiment at the sentence level and optionally aggregate by rows or grouping variable(s)”…“sentimentr attempts to take into account valence shifters (i.e., negators, amplifiers (intensifiers), de-amplifiers (downtoners), and adversative conjunctions) while maintaining speed.”
It was certainly fast, allowing me to take my original data frame of lyrics (grouped by album, track and line number) and calculate a sentiment score. I then set upper and lower bounds for each line so I could use geom_ribbon as follows:
line_sentiment <- sentimentr::sentiment(data$text) data2 <- data %>% filter(title %notin% c("Am I Evil?", "(Anesthesia) - Pulling Teeth")) %>% mutate(linenumber = row_number()) %>% left_join(line_sentiment, by = c("linenumber"="element_id")) %>% group_by(Album, title) %>% mutate(linenumber = row_number()) %>% ungroup() %>% mutate(max = ifelse(sentiment > 0, sentiment, 0), min = ifelse(sentiment < 0, sentiment, 0)) ggthemr(KEA)#custom palette filter(data2,Album == "Kill_Em_All") %>% ggplot(aes(linenumber,sentiment),fill = title,colour = "grey50") + #geom_col(show.legend = FALSE)+ geom_ribbon(aes(ymin= min, ymax = max))+ ggtitle("Kill Em All - Lyric Sentiment Polarity Line by Line") + xlab("Song Line #") + ylab("Sentiment polarity") + facet_wrap( track_n ~ title, ncol=5) + theme_minimal(base_size = 8) In chronological order, and album specific colours, natch:
Those of you paying attention last time might remember this plot:
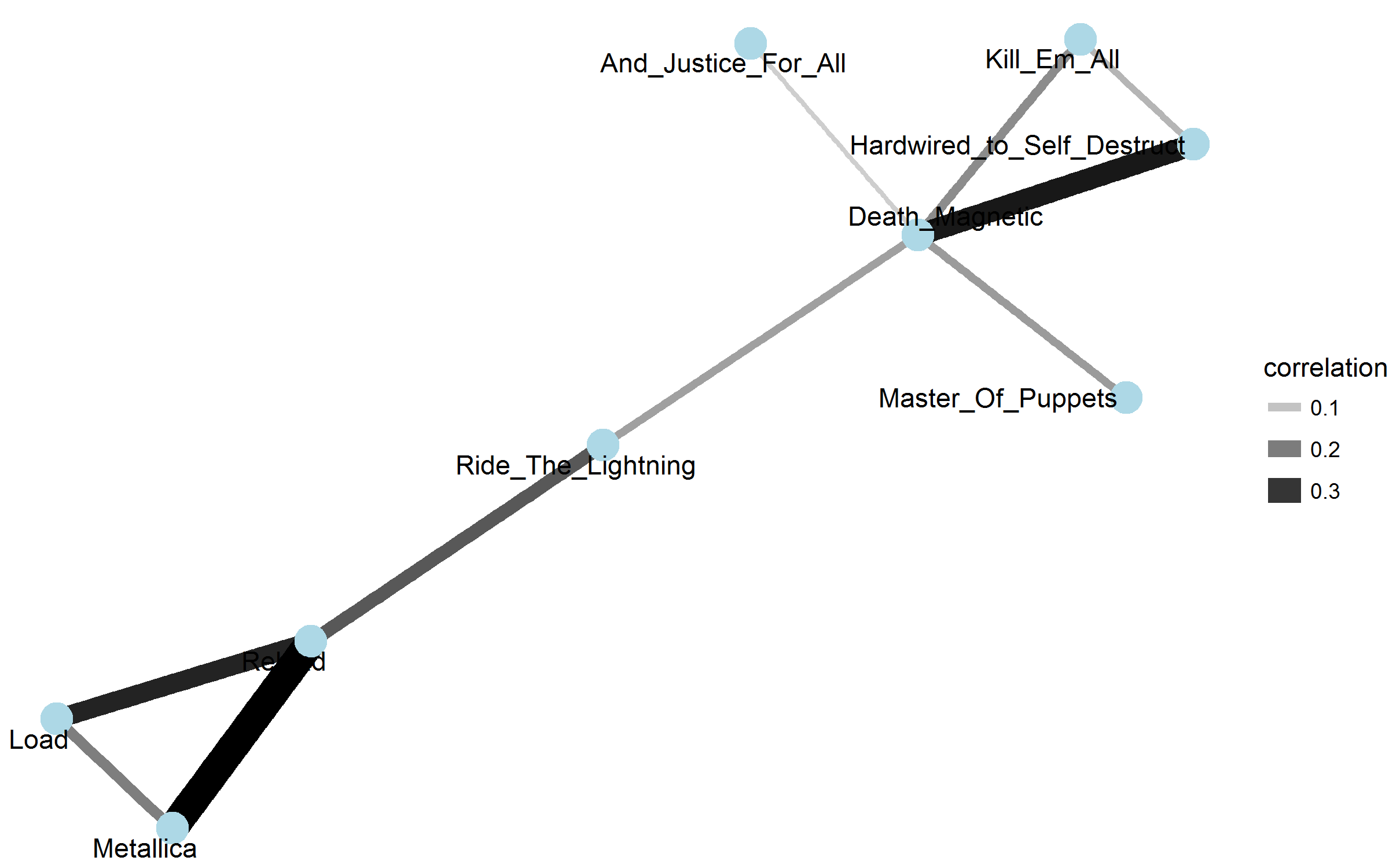
I tried recreating it with different seeds and limits, and that link between album one and ten still holds:
So I thought I should revisit the topic modelling, this time, instead of by album, grouping them into the 90’s releases (Metallica,Load & Reload) and the first, and latest 2 (Kill Em All, Death Magnetic and Hardwired to Self Destruct).
Here are the resulting plots. Alhough I can determine where most of the words are coming from, I’m still not getting much of a feel for a definite “topic” as such:
The 90’s :
Hardwire ‘Em All :
And to finish, you write posts and hope folk like them, and this one went down quite well. Not everyone liked it (hence the title - I am “sad”, apparently) but even so, who cares, because Julia Silge made 2018 an awesome year already :
Stuff like this makes staying up late battling with code worthwhile.
And of course, I get to use cutting edge data science tools and techniques.
That’s got to be worth a “Yeah!”
